The problem with assuming the schedule makes all of the observations so far meaningless is that it ignores all of the non-schedule related factors that could explain a player's performance between one season and the next: offseason workout, coaching, maturity level changing, etc. all are pretty much independent of the following season's schedule. Are you taking any of these into account when concluding that his current results aren't useful in predicting the rest of his season?
For example, Kuznetsov was a much better player under Barry Trotz than he was under Todd Rierden. Every year under Barry Trotz was better than both years he had under Todd Rierden in terms of shot differential metrics, and especially on the defensive side of things. Now Todd Rierden is gone and another experienced coach with a track record of success has been brought in. Is it really that unreasonable to assume that Peter Laviolette has led to a quick turnaround in Kuznetsov's game, especially when most posters agree that Todd Rierden was not a very good coach? People are high on Laviolette and Kuznetsov is one of the most talented players on the team and in the NHL, according to many posters here. Isn't that a reasonable possibility to explain his excellent shot metrics so far? Why are we to conclude that it's the schedule, and therefore his numbers so far are meaningless? I don't think Peter Laviolette is going anywhere any time soon, and I don't think Todd Rierden is going to make his triumphant return to Washington.
Also, I believe you still have yet to address the possibility of random chance being a factor in the game of hockey. If you do accept random chance being a factor in hockey, then you necessarily will conclude that there is no perfect model that will predict future outcomes with 100% certainty. Perhaps the theoretical maximum predictability after 10 games is closer to r^2 = 0.23 than you expect? How do you know one can do much better than this? Have you tested it?
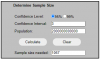
Regarding the bolded above: averages converge very quickly when performing samples. It is rarely if ever needed to exceed a thousand or so as a sample size. If you follow political polling you will see most sample sizes are usually only a few hundred to maybe a thousand or so participants even though there are 239 million eligible voters in the United States, for example. Any sample greater than a thousand or so is unnecessary because there is no point in drilling down to hundredths or thousandths of point in accuracy. Is there really a big difference between r^2 being 0.23 under the method used in the article posted previous, or do you really need it to be shown that it's actually 0.226863428? It'd be a waste of time. Especially since, unlike political polling, it is possible to get truly unbiased random samples of data under the method the author used, so the sample size would need to be even smaller to get a good confidence interval.